
For the last few years, AI image generation has dominated every headline. Nanobanana, Midjourney, FLUX, Stable Diffusion. All of them are impressive at generating visuals. But if you've ever tried to use one of those outputs in a real marketing campaign, you've probably hit the same wall everyone else has.
The text is baked into pixels.
The logo is slightly wrong.
You can't move the headline.
You can't swap the price.
You can't resize it for a different platform without starting over.
It's a flat image, and flat images are not designs.
A growing number of AI research teams have recognized this gap. And a new category of models is emerging to fill it: text-to-design models.
These models don't generate pixels. They generate free-form, multi-layered compositions where every element (text, images, vectors, backgrounds) exists as a separate, editable layer. The output isn't a frozen JPEG. It's a design file.
There are only a handful of models that currently define this space. One is a shipping product. The rest are research papers and open-source experiments. Here's how they stack up.
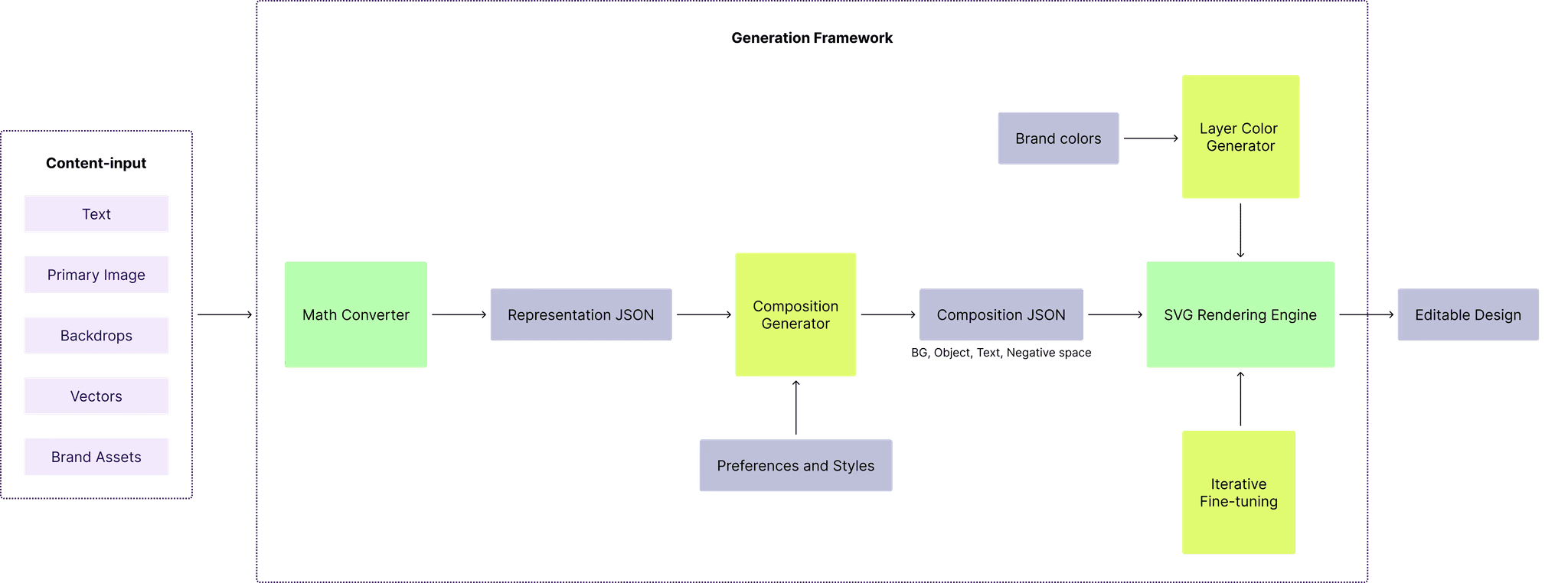
Sivi's Large Design Model (LDM)
We launched our first text-to-design model in June 2023, making it the earliest production system in this category. It's now on Gen-2.5, with Gen-3 on the way.
The core idea behind Sivi's LDM is what we call "atomic design generation". Rather than predicting which pixels should sit next to each other, the model composes design layouts. It treats text as live text, images as individual components, and vectors as vectors. The output is a layered file where every element is independently editable.
What it does
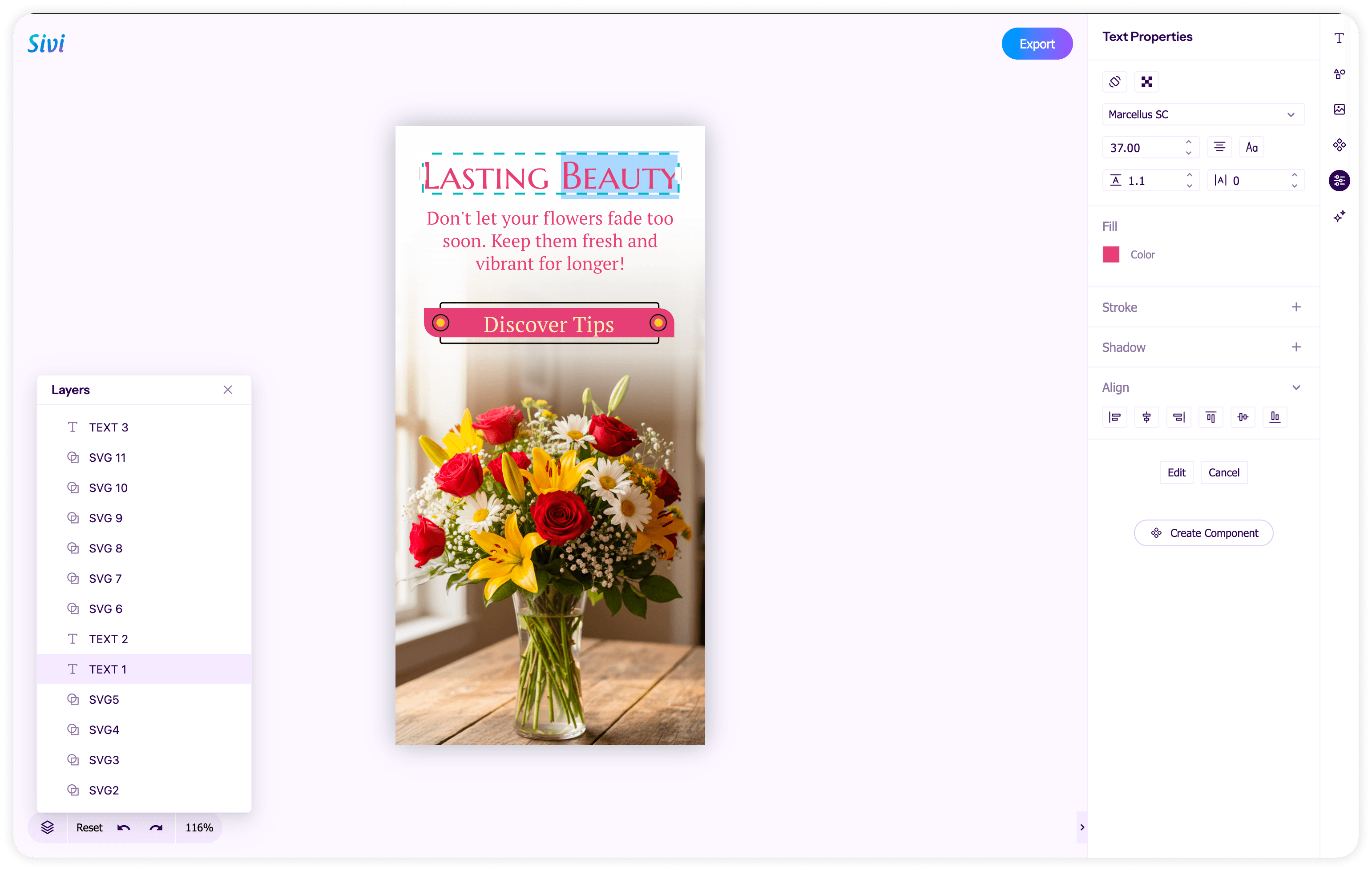
Layered, editable output. Click any element and move it. Change the headline, update the price, swap the background. The text is not rasterized into the image.
Brand compliance. You set up a brand kit with your colors, fonts, logos, and component styles. The LDM applies them consistently. It doesn't guess your hex codes.
Custom sizes. From a 300x250 display ad to a 1920x1080 hero banner. No aspect ratio constraints, no cropping nightmares.
72+ languages. The model composes the layout for any language so typography and hierarchy work in the target language.
Bulk generation. Generate multiple design variations at once for A/B testing.
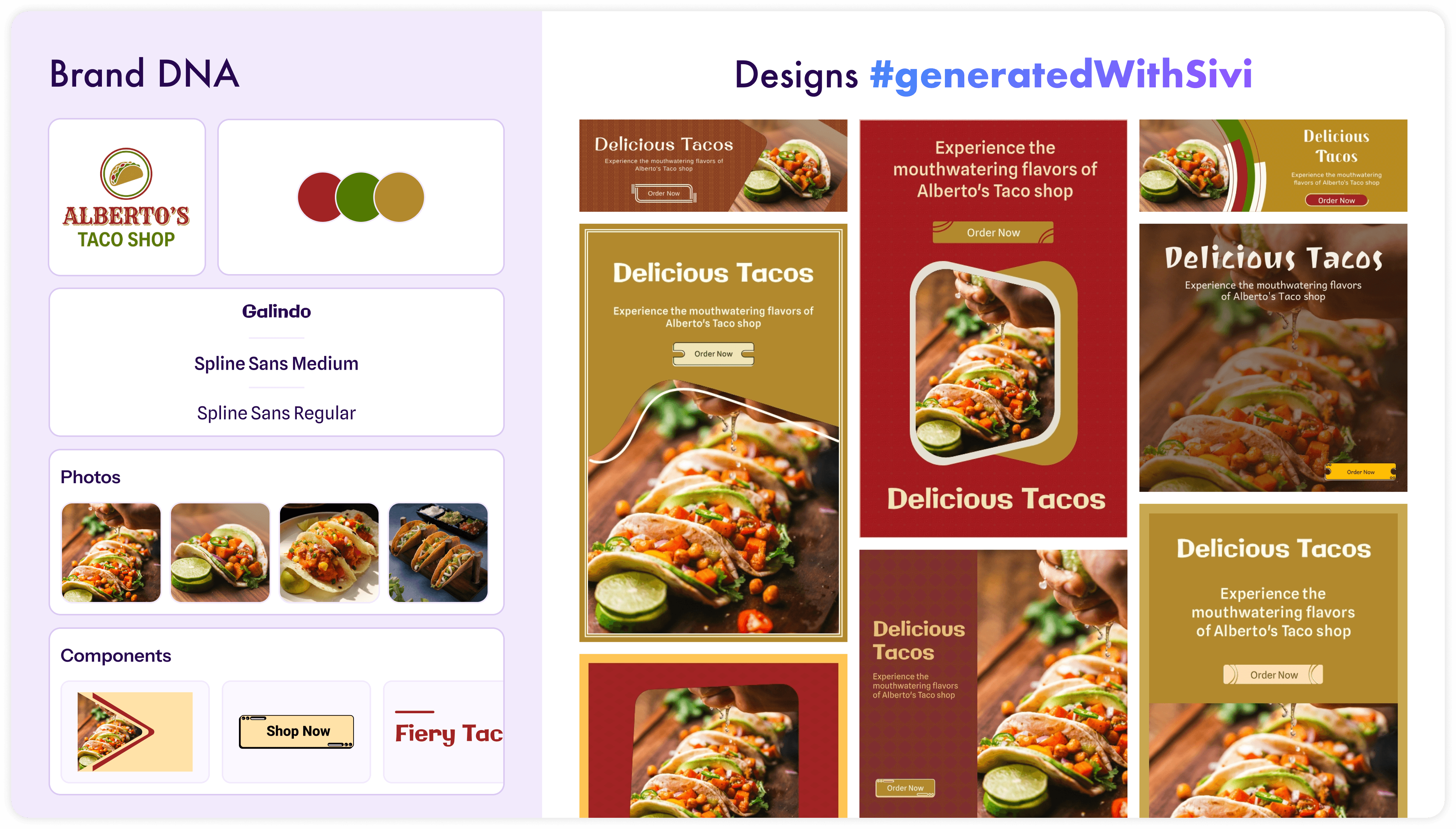
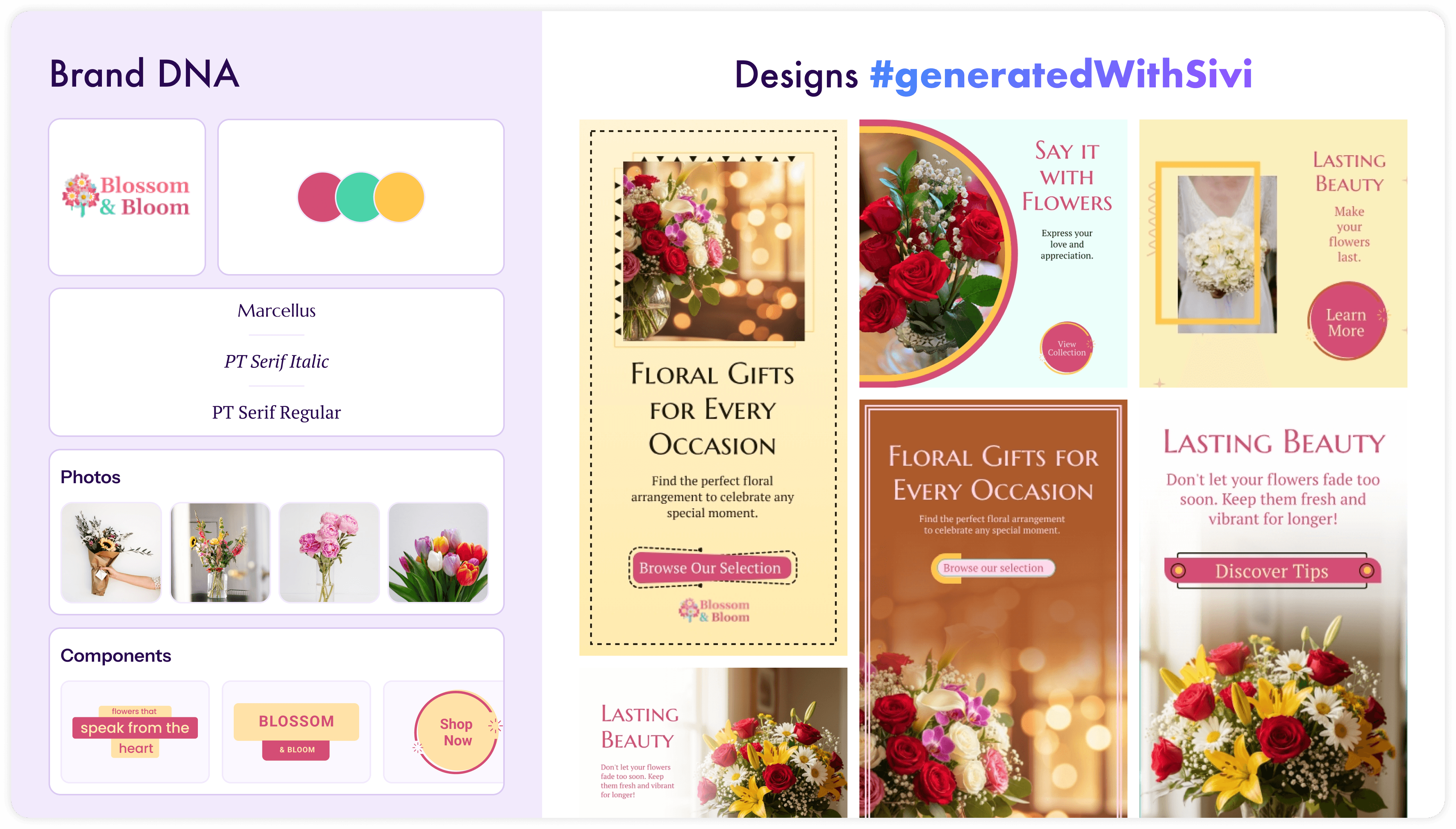
Why it matters
Sivi's LDM is the only text-to-design model you can use right now in production. And it comes with two integration paths that make it accessible to developers, not just end users.
The REST API for text-to-design gives you headless, backend control. POST a JSON payload with your text prompt, brand kit ID, and output size. Get back a layered design with individually addressable components. Export as HTML, JPG, PNG, or PDF. It works for automated pipelines, bulk generation, and any workflow where you need designs generated server-side without human interaction. Ecommerce platforms use it to auto-generate banners for thousands of SKUs. Ad platforms use it so users never leave the platform to build a creative. Email marketing tools use it to match visuals to campaign copy.
The UI SDK goes further. It embeds a complete design studio (generator + editor + export) inside your product. Available as a React component or an iframe for any frontend stack. Your users generate a design, click any element to edit it, and export the result, all without leaving your app. It's white-label ready: your colors, your fonts, your domain. Agencies use it to build branded client portals where each client gets their own brand kit and generates their own assets within the agency's guardrails.
This isn't a demo or a research prototype. Enterprises, agencies, and SMBs are using it to generate ad creatives, social posts, ecommerce banners, and YouTube thumbnails at scale.
ByteDance's CreatiPoster
CreatiPoster is a research framework published by ByteDance in June 2025. The paper is titled "CreatiPoster: Towards Editable and Controllable Multi-Layer Graphic Design Generation."
The architecture has two main components: a protocol model and a background model. The protocol model is a large multimodal network that takes user instructions (text prompts, uploaded assets, or both) and outputs a JSON specification. This JSON describes every layer in the design: text content, font, size, position, z-order, and asset placement. A rendering engine like Skia then turns that JSON into editable foreground layers. The background model generates a matching backdrop conditioned on those rendered foreground layers.
What it does
Multi-layer output. Text and assets are separate, editable layers sitting on top of a generated background.
Flexible input. Accepts prompt-only, asset-only, or mixed inputs. Users can also lock specific element positions or attributes.
Responsive resizing. Can re-layout the same content for different canvas sizes while preserving style and content.
Multilingual generation. Despite not being trained on multilingual protocol data, the model generalizes to Japanese, French, Arabic, and other languages.
Animated posters. Since the output is layered, a video model can animate the background while keeping text layers crisp and editable.
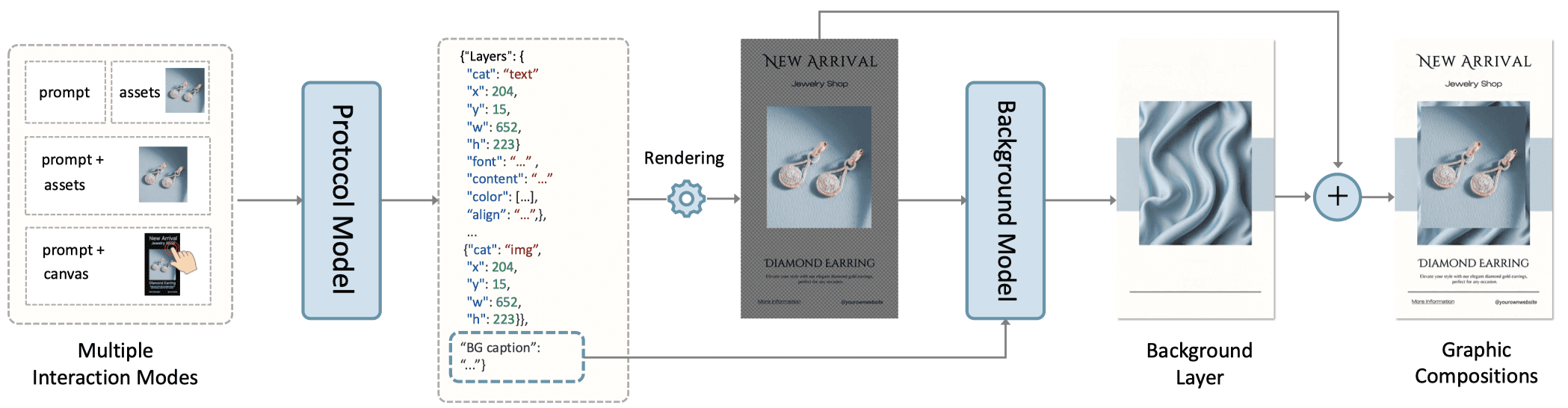

Image Credit - CreatiPoster
Where it stands
The paper claims CreatiPoster is open-source, with promises to release the code, model weights, and a dataset of 100,000 copyright-free multi-layer designs. As of now, none of that has been released. The GitHub repo is empty, and the community has noticed. On automated benchmarks in the paper, it outperformed both open-source alternatives and some commercial systems.
There was an initial integration into Pippit AI (ByteDance's creative tool), though it's unclear whether it's still active. Beyond that, there's no hosted API, no production infrastructure, and no brand management system. Even if the weights and code do land eventually, you'd still need to run the models yourself, build the rendering pipeline, and handle everything from input processing to output delivery.
The paper itself acknowledges that the framework is aimed at "catalyzing further research" rather than serving as a finished product.
What it can't do
The editability pitch sounds great until you look at what "editable" actually means here.
No vector layers. Shapes, icons, decorative elements - they all get flattened into the background image. You can't select a shape and recolor it. You can't move a badge. If it's not text, it's pixels.
Only two layers. You get a background image and text on top. That's the entire layer stack. No separate layers for logos, product shots, or graphic elements.
Text size is locked. The background was generated around specific text placement. Make the headline bigger? The background doesn't know. The whole composition falls apart.
For quick mockups or research demos, that might be fine. For production design work where you need to move things around, swap brand assets, or resize a headline → it's a dead end.
Microsoft's COLE
COLE was published in late 2023 by researchers from Peking University and Microsoft Research Asia. The full name is "COLE: A Hierarchical Generation Framework for Multi-Layered and Editable Graphic Design."
COLE's key insight is task decomposition. Instead of trying to generate a complete design in one shot, it breaks the problem into a hierarchy of sub-tasks, each handled by a specialized model.
How it works
The system runs in three stages:
Design understanding. A fine-tuned LLM (based on Llama2-13B) interprets a vague user prompt like "design a poster for a jazz concert" and generates a JSON with text descriptions, object captions, and background descriptions.
Visual generation. Specialized cascaded diffusion models generate background images and object visuals. A typography LMM (based on LLaVA-1.5-13B) predicts text styling and placement. A renderer then assembles all the components.
Quality assurance. A reflection LMM reviews the output and suggests corrections to text box sizes, positions, and other layout details.
What it does
Intent-to-design. Users don't need detailed prompts. A short intention like "promote a summer sale for sneakers" is enough for the system to plan and generate a complete design.
Multi-layered output. The generated designs have separate layers for background, objects, decorations, and text, making them editable after generation.
Self-critique loop. The quality assurance stage catches issues and adjusts the layout, reducing the need for manual fixes.
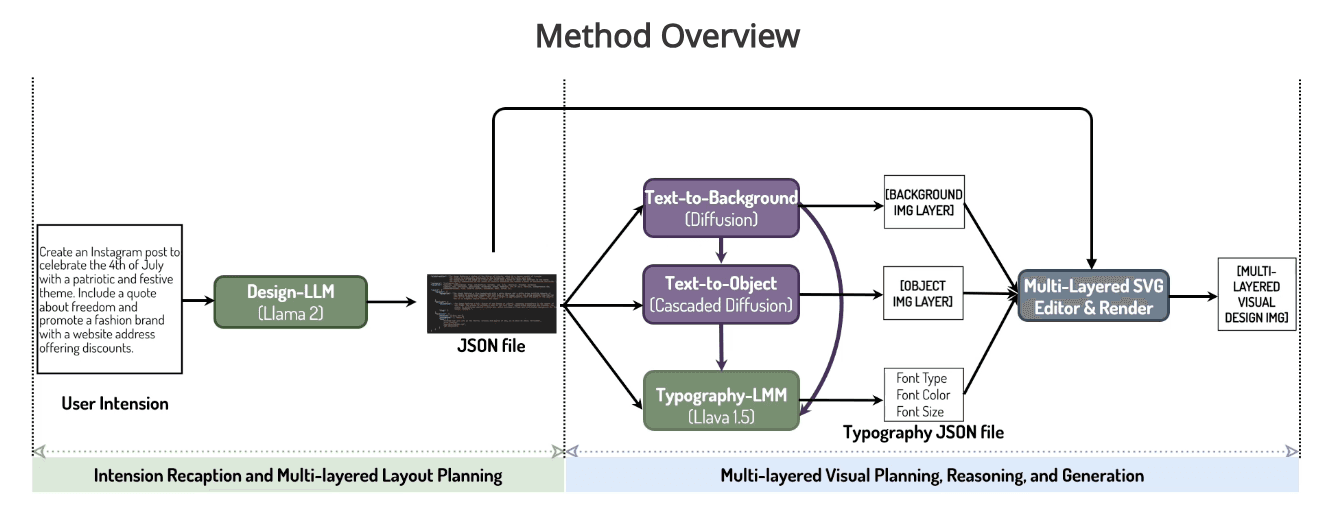
Image Credit - COLE
Where it stands
COLE was tested on about 200 graphic design prompts spanning ads, event promotions, and marketing materials. The results are promising, particularly for covers, headers, and posters.
Image Credit - COLE
But like CreatiPoster, COLE remains a research paper. There's no API, no SDK, and no way to integrate it into a production workflow. The team published a benchmark dataset and project page, but not a usable product.
What it can't do
COLE has the same two-layer, no-vector problem as CreatiPoster. Background image, text on top, nothing else is independently editable. But it goes further in what it restricts.
No brand compliance. There's no brand kit. No way to lock in your colors, fonts, or logo rules. Every generation starts from zero.
Square only. COLE was tested on square outputs. No wide banners, no tall stories, no leaderboards. Just squares.
No user content. You can't give it your copy, your product images, or your logo. It generates everything from a short intention prompt. That works for a demo. Not for a campaign where the copy is already approved and the logo has to be exactly right.
OpenCOLE: the open-source attempt
COLE's code and datasets were proprietary. Nobody could reproduce the results. So CyberAgent AI Lab built OpenCOLE in 2024, an open-source reimplementation using only publicly available data and models. Same three-stage architecture, some simplifications.
It's an honest effort at reproducibility. But it also shows why this approach has a ceiling.

Image Credit - CyberAgentAILab
Where it falls short
OpenCOLE is an honest effort at reproducibility. But it also makes the limitations of this approach even more visible.
Tiny dataset. OpenCOLE trains on Crello, about 24,000 graphic designs. That's not enough to learn the range of styles, industries, and layouts that real design work demands.
Doesn't generalize. Give it a prompt that looks like its training data, and the output is passable. Anything outside that distribution, and quality drops fast. The paper itself shows it lagging behind SDXL 1.0 and DALL-E 3.
No brand compliance. Same story as COLE. No brand kits, no font management, no color systems. It has no idea who the design is for.
Text you can't read. The paper's own analysis calls this out, long sentences with no line breaks, poor color contrast, thin fonts. The text looks like it's there, but try reading it.
Two text blocks. That's it. The typography module generates a heading and a subheading. Real marketing designs have headlines, body copy, CTAs, contact info, disclaimers, prices. Two lines of text doesn't get you far.
OpenCOLE proved the COLE pipeline could be rebuilt with open data. It didn't prove the approach can produce designs anyone would actually ship.
The real difference: research vs. production
Every model on this list agrees on the problem. Flat images aren't designs. The output needs layers and editability.
They share a lot of DNA, too. Multi-stage generation, text separated from background, free-form output instead of frozen pixels.
But there's one question that matters more than any architecture diagram: can you actually use it?
Sivi LDM | COLE / OpenCOLE | CreatiPoster | |
|---|---|---|---|
Status | Production product | Research paper / open-source reimplementation | Research (open-source) |
First published | June 2023 | November 2023 / June 2024 | June 2025 |
API available | Yes | No | No |
SDK available | Yes | No | No |
Brand kit support | Yes | No | No |
Vector layers | Yes | No (merged with background) | No (merged with background) |
Layer count | Multiple (text, images, vectors, backgrounds) | Two (BG image + FG text) | Two (BG image + FG text) |
Text resizing | Yes | Yes (breaks composition) | Yes (breaks composition) |
Custom sizes | Any size | Square only | Supports resizing |
Multilingual | 72+ languages | Not a focus | Demonstrated in a few languages |
Editable output | Yes, full layer editing | Yes, multi-layered | Yes, via JSON protocol |
User content input | Yes (copy, images, logos) | No (intention prompt only) | Yes (assets + prompts) |
Bulk generation | Yes | No | No |
COLE, OpenCOLE, and CreatiPoster matter. They prove that text-to-design is a real category, not a niche experiment. They've pushed the research forward. OpenCOLE built on publicly available datasets. CreatiPoster promised a 100K-design dataset but hasn't released it yet.
But the gaps aren't things you patch in the next version. Two layers, no vectors, no brand awareness. That's not a missing feature. That's how these systems were built. The architecture doesn't support what production work actually requires.
Research papers don't ship campaigns. They don't plug into your marketing stack. They don't apply your brand guidelines at 3 AM when you need 50 banner variations by morning.
What this means for the industry
When Microsoft, ByteDance, and CyberAgent are all investing in text-to-design research, that tells you the industry knows image generation alone isn't enough. Editable, free-form, brand-aware design is where things are headed.
But knowing the destination and building the road are different things. The research models show what's theoretically possible. Their limitations show what it actually takes; vector layers, real multi-layer editing, brand kits, flexible sizing, and infrastructure that works without a machine learning team.
We've been building this since 2023. The LDM isn't a model in isolation. It's a complete system with brand kits, custom sizing, 72+ languages, production APIs. Every element in an LDM design is its own layer. Resize the text, it works. Swap the logo, the background stays. Export to whatever format your pipeline needs.
If you're a developer looking to add design generation to your product, or a marketing team that needs to scale visual production without scaling headcount, the choice right now is straightforward. There's one text-to-design model you can actually use today.
FAQ
What is a text-to-design model?
A text-to-design model generates layered, editable graphic designs from text input. Unlike image generators that output flat pixels, these models produce free-form design files where text, images, vectors, and backgrounds are separate layers you can edit individually.
How is text-to-design different from text-to-image?
Text-to-image models (Midjourney, DALL-E, Stable Diffusion, Leonardo) generate a single flat image. You can't click a headline and move it. Text-to-design models generate multi-layer compositions where every element is its own editable component.
Which text-to-design models exist today for graphic design?
Four are known:
Sivi's Large Design Model (LDM)
ByteDance's CreatiPoster
Microsoft's COLE
CyberAgent's OpenCOLE
Sivi's LDM is the only one available as a production product. The others are research papers or unreleased open-source projects.
Can I use CreatiPoster or COLE in production?
No. COLE and OpenCOLE have no API or SDK. CreatiPoster promised open-source release of code, weights, and a 100K-design dataset, but none of it has been published. You'd need to build the entire pipeline yourself even if they do release.
What is Sivi's Large Design Model?
Sivi's LDM is a production text-to-design model launched in June 2023, now on Gen-2.5. It generates layered designs with true vector layers, brand kit compliance, 72+ language support, and custom sizing. It's available via a REST API and an embeddable UI SDK.
Do text-to-design models support brand kits?
Only Sivi's LDM. You define your colors, fonts, logos, and component styles once, and the model applies them consistently. COLE, OpenCOLE, and CreatiPoster have no brand kit system — every generation starts from scratch.
What sizes can text-to-design models generate?
Sivi supports any size; from 300x250 display ads to 1920x1080 banners to custom sizes. COLE was tested on square outputs only. CreatiPoster supports resizing but hasn't been proven at production scale.
How do developers integrate text-to-design into their apps?
Sivi offers a REST API for backend automation and a UI SDK that embeds a full design studio into your product. No other text-to-design model currently offers developer integration.
——
Author: Ram Ganesan

Ram is the CEO and Co-Founder of Sivi, the generative AI for graphic design. He is a serial entrepreneur who believes in fundamental innovation to help users at scale and at an affordable price point. He has 17+ years of experience in building software products and 6 years of running a business. Over these years, Ram has acquired customers across the globe including some of the top 500 retailers and raised funds from institutional and angel investors. He is an Alchemist Accelerator Alumni, App4India winner, and has 3 patents in NLP and mobile tech.
Unlock the power of generative AI for design and stay ahead of the curve!












